Abstract
Manipulating objects without grasping them is an essential component of human dexterity, referred to as non-prehensile manipulation. Non-prehensile manipulation may enable more complex interactions with the objects, but also presents challenges in reasoning about gripper-object interactions. In this work, we introduce Hybrid Actor-Critic Maps for Manipulation (HACMan), a reinforcement learning approach for 6D non-prehensile manipulation of objects using point cloud observations. HACMan proposes a temporally-abstracted and spatially-grounded object-centric action representation that consists of selecting a contact location from the object point cloud and a set of motion parameters describing how the robot will move after making contact. We modify an existing off-policy RL algorithm to learn in this hybrid discrete-continuous action representation. We evaluate HACMan on a 6D object pose alignment task in both simulation and in the real world. On the hardest version of our task, with randomized initial poses, randomized 6D goals, and diverse object categories, our policy demonstrates strong generalization to unseen object categories without a performance drop, achieving an 89% success rate on unseen objects in simulation and 50% success rate with zero-shot transfer in the real world. Compared to alternative action representations, HACMan achieves a success rate more than three times higher than the best baseline. With zero-shot sim2real transfer, our policy can successfully manipulate unseen objects in the real world for challenging non-planar goals, using dynamic and contact-rich non-prehensile skills.
HACMan
Hybrid Actor-Critic maps for MANipulation
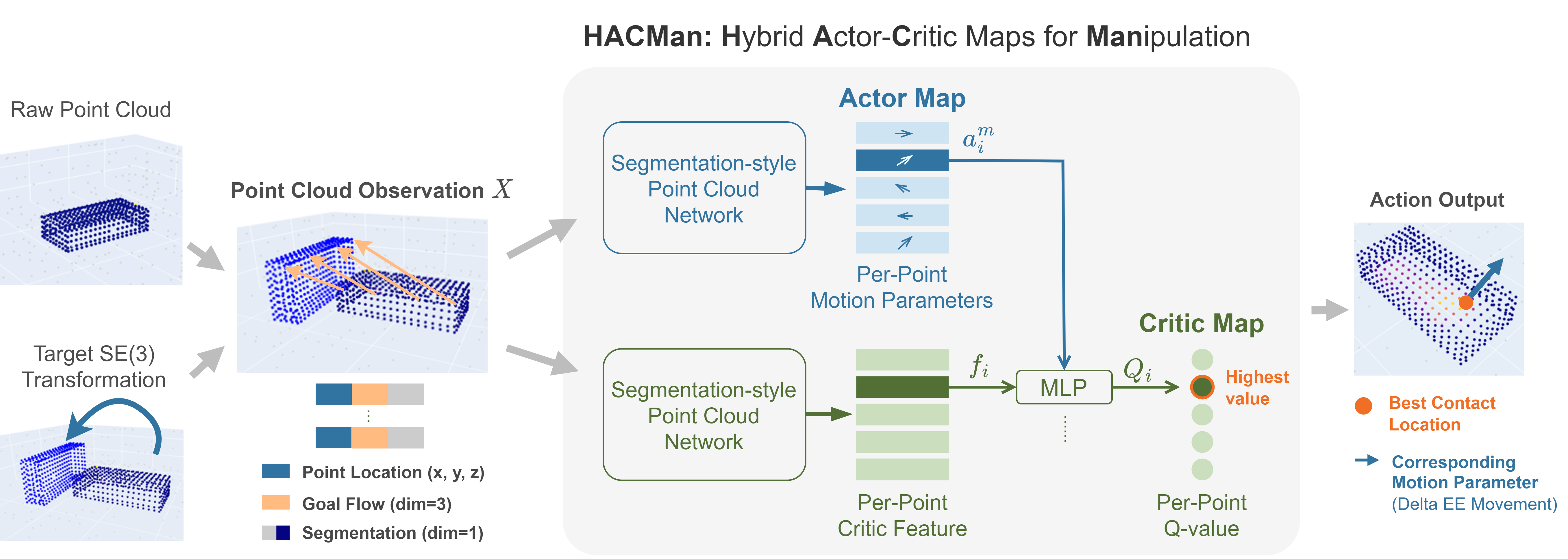
An overview of the proposed method. The point cloud observation includes the location of the points and point features. The goal is represented as per-point flow of the object points. The actor takes the observation as input and outputs an Actor Map of per-point motion parameters. The Actor Map is concatenated with the per-point critic features to generate the Critic Map of per-point Q-values. Finally, we choose the best contact location according to the highest value in the Critic Map and find the corresponding motion parameters in the Actor Map.
Real Robot Results
Successes
Object:
Failures
Failure Case:
Sim Results with Interactive Visualizations
Object:
BibTeX
@inproceedings{zhou2023hacman,
title = {HACMan: Learning Hybrid Actor-Critic Maps for 6D Non-Prehensile Manipulation},
author = {Zhou, Wenxuan and Jiang, Bowen and Yang, Fan and Paxton, Chris and Held, David},
journal = {Conference on Robot Learning (CoRL)},
year = {2023},
}